
EncycNet Project
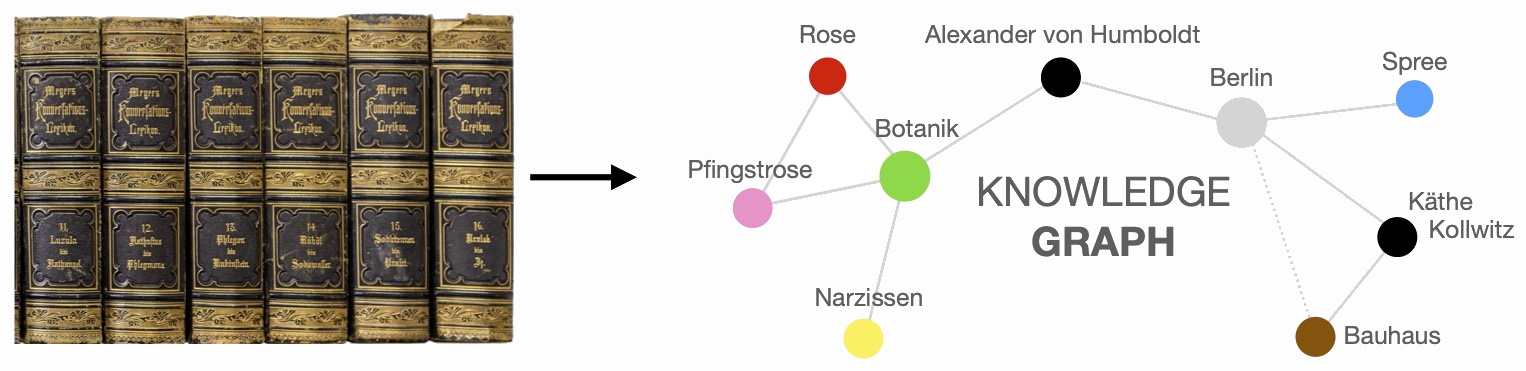
EncycNet, funded by the German Research Foundation (DFG) and begun in 2019, aims to create a new semantic resource for historical German in the form of a richly annotated knowledge graph (a nodes and edges network). By linking the knowledge contained within thousands of encyclopedia entries via machine learning classification and semantic web annotation, EncycNet provides a unique resource for a variety of historical, cultural, and computational linguistic research goals.
{kind=link}
Publications and presentations
- Thora Hagen, “Domain Adaptation with Linked Encyclopedic Data: A Case Study for Historical German”, Computational Humanities Research Conference, December 2024.
- Thora Hagen, Fotis Jannidis and Andreas Witt, “Mental Maps in EncycNet: Exploring Global Representation in a Historical, German Knowledge Graph”, DH2024, August 2024.
- Thora Hagen, Leonard Konle, Erik Ketzan, Fotis Jannidis and Andreas Witt, “Tracing the Shift to ‘Objectivity’ in German Encyclopedias of the Long Nineteenth Century”, DH2023, July 2023.
- Thora Hagen, “EncycNet: Graphen-basierte Modellierung von historischem, enzyklopädischem Wissen”, Forschungskolloquium ‘Digital History’, June 2023.
- Thora Hagen, “Von A bis Z: Überlegungen zur Erstellung eines Wissensgraphen aus historischen Enzyklopädien”, DHd 2023: 9. Tagung des Verbands ‘Digital Humanities im deutschsprachigen Raum’, March 2023.
- Erik Ketzan, Thora Hagen, Fotis Jannidis and Andreas Witt, “Quantitative Analysis of Gendered Assumptions in a Nineteenth-Century Women’s Encyclopedia”, DH2022, July 2022.
- Andreas Witt, Thora Hagen and Fotis Jannidis, “Introducing EncycNet: Graph-based Modeling of 19th Century German Encyclopedic Knowledge”, 5th Annual GHI Conference on Digital Humanities and Digital History, June 2022.
- Thora Hagen, Fotis Jannidis and Andreas Witt, “Word Sense Alignment and Disambiguation for Historical Encyclopedias“, 6th international conference on Graphs and Networks in the Humanities, February 2022.
- Thora Hagen, Erik Ketzan, Fotis Jannidis and Andreas Witt, “Twenty-Two Historical Encyclopedias Encoded in TEI: A New Resource for the Digital Humanities”, LaTeCH-CLfL 2020: 4th Joint SIGHUM Workshop on Computational Linguistics for Cultural Heritage, Social Sciences, Humanities and Literature, December 2020.
Data
- TEI-transformed corpus and ODD
- Original XML corpus
- TEI transformation with XSLT
- CSV data of Wikidata alignment and relation extraction
- Application for data exploration, including Wikidata alignment
- EncycNet Knowledge Graph (RDF)
Team
- Fotis Jannidis, University of Würzburg
- Andreas Witt, IDS Mannheim & University of Cologne
- Thora Hagen, University of Würzburg
- Erik Ketzan, University of Cologne (July 2020 - Sept. 2021)
Research assistants
- Corinna Keupp
- Maximilian Supplieth
- Nicolas Werner (April 2021 - Sept. 2021)
Contact
Thora Hagen
Acknowledgements
Thanks to the German Text Archive (Deutsches Textarchiv), especially Bryan Jurish, who generously performed the orthographic normalization, lemmatization and Part-of-Speech tagging of all encyclopedia texts using CAB.